
061. BSoD to Watson: The Reliability Journey
"20 percent or so of most frequently occurring crashes accounted for more than 80 percent of all crashes" — our discovery of the distribution of bugs and crashes

Happy New Year! I want to offer a short but sincere thank you to all the subscribers, readers, and sharers who have made the past eleven months of Hardcore Software an incredible experience in sharing, learning, and remembering. It is an honor to continue to share the stories and more importantly the lessons of the PC revolution as experienced in the early days.
This is a free post for the new year as a thank you but also because so many have struggled with the topic over the years. Sometimes when talking about PC crashes, I feel like offering an apology on behalf of all the engineers out there who really were doing their best.
Note: This post is best read via the link due to length and images.
Back to 060. ILOVEYOU
PCs used to crash a lot, a whole lot. PCs routinely crashing, freezing, hanging (various ways to describe a computer that has ceased to function) and losing work were the norm. Over about twenty years of engineering and iteration, the PC experience changed dramatically for the better, with vastly more reliability and higher quality. Now I recognize even typing that should make for a protracted thread on Hacker News or Reddit where everyone shared the crashes that just happened today or happen “constantly”. This is the story of going from a world of nearly universal quality and reliability problems to a literal world-changing innovation that dramatically altered the path of PC quality.

My first semester in college staffing the shared computer facilities where nearly everyone used minis, mainframes, terminals, and card readers. If there were problems, it was almost never something IBM did and almost always some form of “error between the chair and keyboard” as we used to say. When I returned to the Spring semester, Macintosh invaded the terminal rooms. My job dramatically changed. Now I was full time on Friday nights helping people to recover corrupt files from floppy disks after the new Apple MacWrite crashed and “ate” their work. After a few weeks, our team of operators started to share best practices: save your work every hour or so, save to a new file, keep papers under about 10 pages, print drafts if possible, don’t use too many fonts and sizes, and finally if you’re doing a big restructuring then save those deleted sections to another file to reuse. Using MacWrite to write a term paper at the end of a semester was, quite honestly, a risky proposition. I dealt with more than a few classmates who lost their 10-page papers hours before deadline. Lost. Gone. Evaporated. The only thing to show for the work was a useless file and an error message on the screen “Sorry, a system error occurred” with a little cartoon bomb as if humor was appropriate.1
That was state of the art. Windows wasn’t far behind. By 1990 with the release of Windows 3.0, Microsoft would introduce its own brand of crashes to the world. Given the rapid rise of PC sales, it was the PC that assumed the mantle of king of crashes. Frustration with PCs crashing, losing work, or just being hard to use was entirely the norm. As we learned from the Stanford researchers who provided the inspiration for Clippy, the precision and exactness of the PC led PC users to assume when something went wrong it was their fault. The PC itself was not the problem.
It was certainly our fault. We were making the software, but we were also making crashes seemingly as fast as we were making features.
Any visit to watch someone use Microsoft Office illuminated the nail-biting, edge-of-seat, stress-inducing experience of using a PC. Our difficult to understand user-interface and faulty-software engrained a generation with defensive usage patterns: save, copy, backup, print, and so on. Even the most basic operations such as reorganizing a long memo or rearranging slides came with a preamble that involved saving the file “94MEMO2.ORI” or some other equally obscure name. Using a command that you weren’t sure of, then of course save your work first because you had no idea what might happen.
A series of changes in how we designed interface and engineered products led to a markedly improved experience and a step-function improvement in product quality.
The journey starts with the most simple and obvious command: Undo.
Most software in the ’90s only worked in one direction, making changes, or destructive changes as we called them. To revert back to what was there previously, an opposite command had to be applied. Clicking again un-bolded a word and it went back to normal, for example. Same with text pasted in one spot: delete and paste again. As programs became increasingly complex, operations were becoming more destructive. Importantly, reversing an operation could be entirely unintuitive, such as changing a chart, a notoriously complicated task or simply moving text with the mouse instead of copy and paste.
People developed ways to cope with this complexity. Prime among them was the use of saving a copy of a file before embarking on big changes and learning how to hit save often. This too had drawbacks. Keeping track of copies of files or saving and then losing old changes that might be useful—it all added to the mental overhead of defending yourself against the whims of software.

Inventing Undo seems lost to history. There were many approaches over many years including Microsoft’s CharlesS when he was at Xerox PARC and even earlier Andries van Dam at Brown University, pioneer in hyperlinks and world-renowned teacher to many and original advisory board member to Microsoft Research). Many specialized products such as Adobe Photoshop and Autodesk AutoCAD introduced undo relatively early. In Office, many people developed Undo—a feature that differentiated Office from most all other software especially considering the complexity of Office across words, pictures, and numbers. Not only did Office create Undo and implement it across products, but for each release it improved.
Office10 introduced multilevel undo across products, extending Undo to a nearly unlimited number of commands—like opening a file, making many changes, and then reverting back to the original just by clicking Undo. All of which could be undone with Redo. Undo and Redo, two simple buttons, represented thousands of hours of work, reducing untold amounts of stress and angst. Office was not the first with the capability, but it was the most widely used, most broadly implemented, and perhaps the most thorough.
Some of the best innovations, like Undo/Redo, while undramatic are both obvious and seamless and often taken for granted, missed only when absent. The early web browsers, though they touted ease and simplicity over Windows and Office, lacked the kind of safeguards being built into Office like Undo/Redo. The analogous buttons in a browser, Back and Forward, failed to work correctly most of the time, and still often don’t.
Undo/Redo also reduced phone calls to corporate help desks. As PCs were being deployed across industries and jobs, companies were pushed to provide support, and that meant on-call telephone support for employees. Windows and Office were sold to LORGs in such a way that the support burden was maintained by the customer, not by Microsoft. Much to the surprise of most individuals at big companies, they could not call Microsoft for help, and if they did they were routed back to their own company or offered a paid incident. Microsoft created a large support staff, but it was only for retail customers. Undo/Redo changed the paradigm of learning how to use Office. Instead of fear, people learned they could try something and if it worked, great, and if it didn’t work it could be undone, or redone. We reduced the risk of using features and the need to ask another person for help. Just try something and if it didn’t work, undo it. The oft-repeated sequence of undo/redo would become an substantial blip in our instrumented studies and when watching people use Office in our usability labs.
Undo/redo did not, however, change the scariest part about using a computer: a crash. Crashes happened at any time, leaving a user staring hopelessly at the screen, often a blue one, hours of work lost to the ether. The lucky person didn’t lose much if they happened to have just hit the magical Save button, but nobody ever expected a crash. The worst type of crash lost the entire file, not just the changes since the last save. A so-called corrupt file became the worst of PC nightmares—you know your work is in there somewhere in the file but you can’t get it out because Office just fails at trying to open the file. A whole cottage industry of file recovery services grew up around PCs.

The loss of work was so profound and such a part of the fabric of using a PC at work that “my computer crashed” replaced “my dog ate it” as an excuse. Crashing computers and lost files were the subject of internet jokes (we didn’t call them memes yet), newspaper cartoons, and an all-too-common film and TV plot device. Who among us has not stopped to snap a photo of a crashed kiosk at the airport or supermarket? Crashes were also the leading single subject of calls to Microsoft’s Product Support and a major cost to customers. These calls were futile at best and there was little a support engineer could offer. Whether senior government officials, expensive lawyers facing court deadlines, or famous authors escalating their way through support, there was almost nothing we had to offer them, VIP or not.
As if crashing weren’t bad enough, the way software handled a crash was, well, laughable, especially in hindsight. I don’t know how many years it took for carmakers to give up and create a red Check Engine light, but the first two decades of PC software were a journey of absurdity, making every crash a bit of a mystery.
When software tries to do something that is literally impossible the processor simply stops and the whole PC ceases to work. That’s a bug, a crash. It is the most severe kind of bug and it comes from programmers writing incorrect code. Technically a bug is any time anyone believes the software behaves differently than expected, even if it does not cause a crash. There are as many ways to crash as there are programmers. The program is trying to do something that doesn’t make sense, such as fetch some data from a location in memory that does not exist or invalid math such as divide by zero. These failures are routine, but not all programs handle them gracefully. Good programmers write defensive code. That means they always check to make sure operations make sense before trying them and after they execute. Even with the best intentions, not every line of code is defensively programmed as DougK ingrained in us in Applications Developer College—it isn’t always practical, and it doesn’t always come for free.
Crashing bugs can be difficult to find and fix. Many times, a crash happens intermittently or appears because a different series of steps are used. The bug may depend on the information being processed—how big a document is being edited or maybe the series of formatting commands, how much free memory the computer had, what else is running at the same time, or even what type of printer or display is in use. Bugs appear anywhere, not just in the code in an application. They could be in the Operating System code, such as MS-DOS or Windows, in the application, like Word, or even in the code that makes a certain model of printer or video display work, but what the end user sees might be totally unrelated to where the coding mistake happens to be.
These conditions make finding bugs an enormous and time-consuming challenge. One of the greatest programmer skills is finding bugs in other people’s code. Legendary programmers in Apps such as JonDe, DuaneC, JodiG, RickP, ScottRa, and DougK were held in high esteem, not only because of the bug-free code they wrote but also for the bugs they diagnosed in other’s code.

I created many bugs on my own before Microsoft and learned how to find bugs planted in Microsoft code during my training in ADC, but I learned about my first commercial bug during my first summer at Microsoft. DanN my lead in ADC shared (JonDe refreshed my memory of the specifics) the story of the infamous “Sindogs” bug in Excel 2.0, which was the first Windows version that shipped with Windows 2.0 about 18 months before I arrived. The bug manifested itself when an important part of Windows, a plain text file with all the system settings, was corrupted—in the file where it was supposed to say “[Windows]” it somehow was changed to “[Sindogs].” Neither the word Sindogs appeared in any code nor did any code write that string, so its appearance was rather mysterious. The bug took days to materialize and was only discovered after Excel testers ran an automated test to create and print charts over and over, for many hours. Eventually, through a significant amount of sleuthing, the team narrowed it down to a bug in drawing code in Windows, which was called when adding arrows to charts then printing them on old-school dot-matrix printers. There was a memory corruption, which changed the contents of the settings file that was in memory before it was saved to the disk. Stories were told about it for years. The Excel team even renamed their file server after the bug, and through Office 97 we connected to the server “\SINDOGS\REL” (REL was short for release) for release builds of Excel.
Imagine tracking down a crazy bug after the product was in market and trying to figure out what caused it, then multiplying that by all the possible printers, video cards, and programs involved. Looking back, it was an engineering marvel that anything worked at all. In moments of frustration, or desperation, that is what we told ourselves.
In the early days of PCs before Windows, crashes froze the computer—nothing worked, not even banging on the keyboard. The only recourse was to turn the computer off and start over, losing unsaved work and causing a potentially extreme emotional moment. In the earliest days of automobiles, drivers had to be mechanics for fear of getting stranded by flaky engines—PCs were sort of like that.

As PCs evolved, so did crashing. Windows developed a new way of dealing with crashes. Rather than freezing the computer and doing nothing, Windows 3.0 offered the first crash-handling experience known by the most friendly of names: Unrecoverable Application Error, or UAE. Instead of freezing, a crash offered a big white message box that read:
UNRECOVERABLE APPLICATION ERROR
Terminating current application.
OKThe message offered a single “OK” button, which was ironic because nothing was actually OK.
Not only was this not helpful, it offered no solutions to fixing the problem. Useless, yes, but Macintosh did not do much better, offering a similarly useless message, albeit one with a nice sound and a newly famous graphical bomb exploding. The text of the message apologized, “Sorry a system error occurred” and the one button offered not OK but “Restart” as a worse reminder of the state of affairs. In either case, there was effectively nothing to do other than “don’t do that again,” even though no one was ever sure what they did to cause the crash.

That was the state-of-the-art PC experience until Windows 3.1 in 1991, which introduced an innovation that began a 10-year journey into making software more robust in the face of crashes. While a little nicer and equally useless to end-users, the new UAE message was at least useful to software developers. Though, in hindsight, it was laughably hostile given customers were about to lose work:
Application Error
WORD.EXE caused a General Protection Fault in
module KRNL386.EXE at 0002:4356
CLOSEThis message had a single Close button. The sequence was meaningless to anyone who did not design microprocessors for a living. Who was this “general” and from what army? As expected, the company quickly abbreviated this as GPF and we entered a new era of tracking these GPFs and certainly talking about them in the cafeteria all the time as a new Micro-speak term.
Over time there were many variations of these crash messages. None were particularly helpful. In fact, they became more techie and contained a broader array of techno-language. Meanwhile, Apple stuck with their exceedingly simple and apologetic system bomb.
In Product Support Services (PSS) and in our bug databases (called RAID) we tracked these snippets of data. When customers called, they read this screen and jargon to the support engineer who then entered it into a tracking system. PSS would diligently record all the numbers and produce a monthly report detailing all the crashes. After a while they could talk about some of the crashes happening more frequently than others because of the similarity in the memory locations of the crash. Because so many crashes were due to settings and configurations unique to a customer environment, PSS became adept at walking through a whole series of potential changes in an effort to simply alter something in the environment to remove the crash. All of this, from the lists of crashes to the sorcery of changing settings, was entirely inadequate but it was the best people doing the best they could. There was almost nothing we could do on the development team with these mere nuggets of data as we searched tirelessly for more information and steps to reproduce crashes.
The primary problem was a lack of information, such as what steps preceded the crash or what else was running. We needed the full state of the computer at the time of the crash, not just the place it crashed. What else is in PC memory, and what else was going on at the time of the crash?

Windows needed a flight data recorder (a.k.a. black box), like on an airplane. A member of the Windows team developed a tool called Sherlock, which was just that, a flight data recorder for PC crashes. Right away, companies ran the program, eventually renamed Dr. Watson due to the discovery of a naming conflict with a commercial product. Shipping with Windows 3.1 Dr. Watson featured an icon of a doctor and a magnifying glass, cementing a new level of approachability for Windows crashes. If customers called PSS with a crash, PSS directed them to restart their PC with Watson running (which could be downloaded from AOL or CompuServe) and try to crash again intentionally to gather additional information to email to Microsoft.
The information was entirely gibberish to customers but super helpful to developers. After the crash, a file was left on the PC and could be sent to Microsoft. The internet was still not in widespread use, particularly with LORG customers, but enough people had email. From there developers and testers could combine that with some information about what a customer was doing at the time of the crash. This helped PSS to help product teams fix real-world crashes.

The relentless march of non-actionable and awkwardly worded crash messages from Windows continued with Windows 95. This revolutionary product aimed to make PCs easier to use, but it did not put a stop to crashes. Windows 95 did update the experience to put much more information in front of the user:
This program has performed an illegal operation
and will be shut down.
If the problem persists, contact the program
vendor.Following this screen was what could only be defined as a wall of numbers and letters, which a user could select and copy to email to Microsoft, after they hung up with PSS because they had dial-up.
Unlike General Protection Fault, which was funny, Illegal Operation was scary. We were telling people that their computer did something illegal. I was recruiting at a university outside the United States when a bilingual student asked me if anyone reviewed the translation of this message, because in her native language the translation sounded like the authorities were on their way to confiscate the computer or at least issue a fine.

Over time to become more friendly and perhaps offer a choice, the blue screen was, by some measures, improved as it became the primary crash experience:
A fatal exception 0E has occurred at 0028:CD0034B23. The current application will be terminated.
* Press any key to terminate the current application.
* Press CTRL+ALT+DEL again to restart your computer. You will
lose any unsaved information in all applications.
Press any key to continue _The modern 32-bit Windows NT product took the new blue screen to a whole new level. When Windows itself crashed the screen would be filled completely with the numeric contents of memory. The only indication that nothing good was about to happen was the “*** STOP:” that appeared at the top of the screen indicating that the computer needed to be restarted. This is by most accounts the original Blue Screen of Death (BSoD).

While an improved Dr. Watson tool was available and helpful, most customers came to loathe the BSoD experience, which became a meme for PCs. In hindsight, this was a particularly hostile design. BSoD also became Micro-speak but rose to a higher level of pop culture, appearing as the de facto method to represent a crashed computer on TV and in movies.
Windows NT, with its modern operating system design, did not remove crashing from the PC experience, but at least crashes no longer required a full computer restart. That was good. Users still lost their work but only for the program that crashed (as if that was any consolation). For IT professionals, the Dr. Watson information was always saved on the PC and could be fetched remotely and shared with Microsoft.
We were making progress. The additional information and the inclusion of Dr. Watson technology with the broad use of email and new online support meant that development teams received detailed information about crashes. Tracking down a single crash was time-consuming, but we gained an understanding of the real-world product experience.
We increased our level of commitment to eliminating crashes but were only making marginal progress. As Office usage grew, the absolute number of crashes also grew, and the sheer number of them was increasingly noticeable. We continued to double down on taking reports from PSS of the top crashes and fixing them, proudly announcing in a service pack that we removed top crashes. Still, LORGs were complaining and sharing stories of those mission critical documents that were lost in the wee hours of the morning before the big meeting or contracts that were lost just as the final changes were made, and even within Microsoft the stories of lost documents and spreadsheets were too numerous to count. Yet we also knew Office was among the highest quality—least crashing—software on the market.
We desperately needed a breakthrough.

Over the holidays in December of 1998, as we were in the final bug-fixing stages of Office 2000, KirkG (one of my first Microsoft friends) sent me a note saying he wrote up an idea. He banged out the note on his preferred 83-key Compaq keyboard from the 1980s. He had posted it on http://office10 in the total cost of ownership team section. It was shocking because I had known Kirk a decade and could not recall him writing a memo or even a long email about anything. He was a hacker’s hacker who preferred low-level assembly language whenever possible.
Two pages, the memo featured a graphic at the top of D. W. (Dora Winifred) from the animated TV series Arthur. Kirk and Melissa (who recently retired as MelBG) gave birth to their first child and thus were steeped in the children’s culture. The use of D. W. was a play on Dr. Watson (eventually only Watson). Kirk wrote:
DW is an update of Dr. Watson. Its purpose is to extract information about a crash, and establish communication with Microsoft.com. If the bug is known to have been fixed in a service release, DW will assist in installing the SR. If the bug has not been found or fixed, DW will transmit necessary information (stack trace, etc.) to Microsoft.com such that we can fix it.
Why. Customers hate crashes. Of all the things wrong using PCs, nothing is more in-your-face frustrating than a crash. Microsoft has a reputation – rightly or wrongly – for shipping buggy software, and to a large extent, buggy == crashing. We should make every effort to find and fix crashing bugs, and we don’t. We make every effort before shipping [emphasis in original], but once out the door it drops precipitously. With web-based communication, this needn’t be.
Kirk was clear, to the point, and he was right. What Kirk proposed was a sweeping change in how we handled crashes. Using the web, all of about three years old, to create a closed loop from the moment a PC crashed until the bug was fixed. Updated software could be downloaded after we diagnosed and fixed the problem.
Kirk built his idea from an architectural feature in PowerPoint 2000, an attempt to more gracefully handle crashes by giving users a chance to save a file when a crash occurred. While a huge improvement, it did not address the root cause. In a few sentences, Kirk extended PowerPoint’s idea of handling a crash straight from the customer’s PC into the debugger at a developer’s desk.
Instantly, this was a profound change in software. While excited, everyone underestimated exactly how this changed software development. For years to follow, I gave a recruiting talk to college students, detailing the innovation in Watson as among the biggest changes to programming and computer science I experienced.
It truly was.
 prove what we know and don’t know. LEARN TO LOVE THE DATA! LEARN TO FEEL UNEASY WITHOUT THE DATA!")
Like any feature, going from spec (generously calling Kirk’s two-pager a spec) to a full-fledged feature was a journey. In this case, DW was the first time Office connected from a PC to the internet, to Microsoft specifically, and that had repercussions. During the late 1990s, trust in Microsoft was not exactly in abundance (trials, viruses, GUIDs, Y2K, and so on). We were gaining traction with LORG customers who would raise deep concerns about PCs “phoning home.”
Microsoft designed a feature that automatically sent information back to Microsoft, which seemed scary on the face of it. The world was starting to realize the implications of the internet and how it could be misused even while serving so many positives.
Unlike many features of Office, this feature had little by way of user experience but did require a great deal on the back end in Microsoft’s new data centers. The sheer force of will needed to stand up a set of servers and connect them to the internet was incredible—the whole company seemed to fight against it. Changing assumptions of what and how teams operated within a big company was a lot of work.
Watson was a small bit of code that was always running in every Office application. When an app crashed (it wasn’t supposed to, but if it did) Watson gathered the state of the program (what was going on in memory) at the time and packaged this up into a small minidump (also called a CAB, compressed cabinet file). In contrast to a fulldump of everything in the system, it was much smaller and could be sent to Microsoft when and if the PC was connected to the internet. The first step was to make sure CAB files were anonymous, containing no identifying information. This sounded easy. Thinking back to GUIDs and metadata covered by the New York Times, there were challenges. Basic items like the serial number of Office or the hardware address of the network card were omitted. Identifying the PC or human submitting a crash was meaningless to us, but we needed to find a way to convince people that was the case.
The memory and state DW gathered might have contents of a document entirely private to the user or information like a name and address or worse. Even though we could not trace back to a person or PC, the mere presence of this information could be perceived as troubling. EricLev, who moved to OPU after working on Word HTML, designed a user interface that allowed customers to see every single byte of information transmitted to Microsoft. It was one click away from the crash dialog. We appreciated designing for full transparency, but we knew people would be reluctant or even creeped out.
The combination of the location in memory of the crash, the program, and a few other items made for a unique crash signature, or as it was called a Watson Bucket. We enabled Watson early in the development cycle for testing. There were tons of crashes that happened then and mostly we were exercising the system, trying to understand how the flow from crash to bucket to debugger to fix worked.
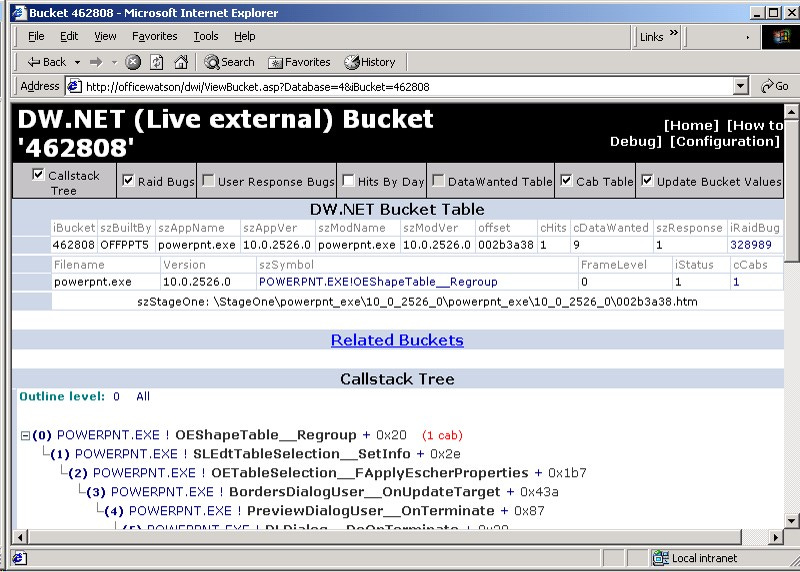
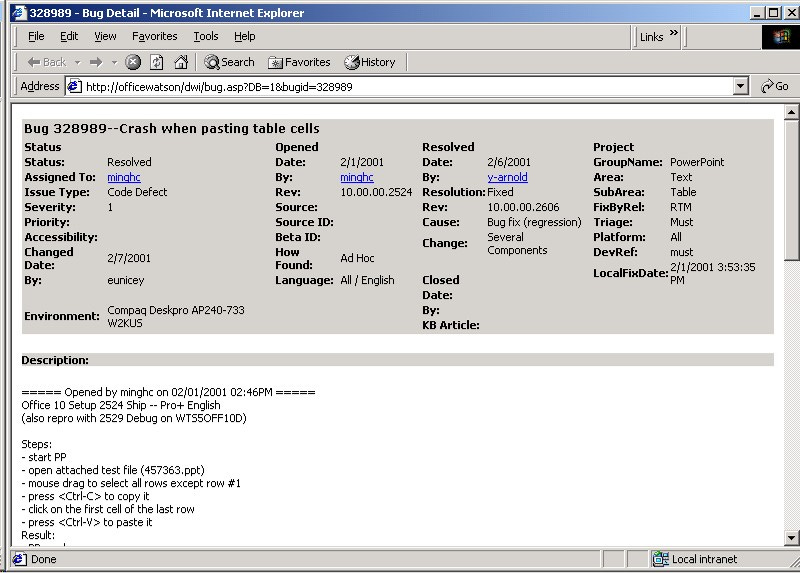
We learned how quickly crash reports fell into buckets representing a single bug. The more hits a bucket received the more frequent the crash. We began to see that while there were many different crashes, the majority of them could be attributed to a small number of buckets. In other words, if we fixed a few bugs we eliminated a huge number of crashes, dramatically improving the reliability of the product for everyone.
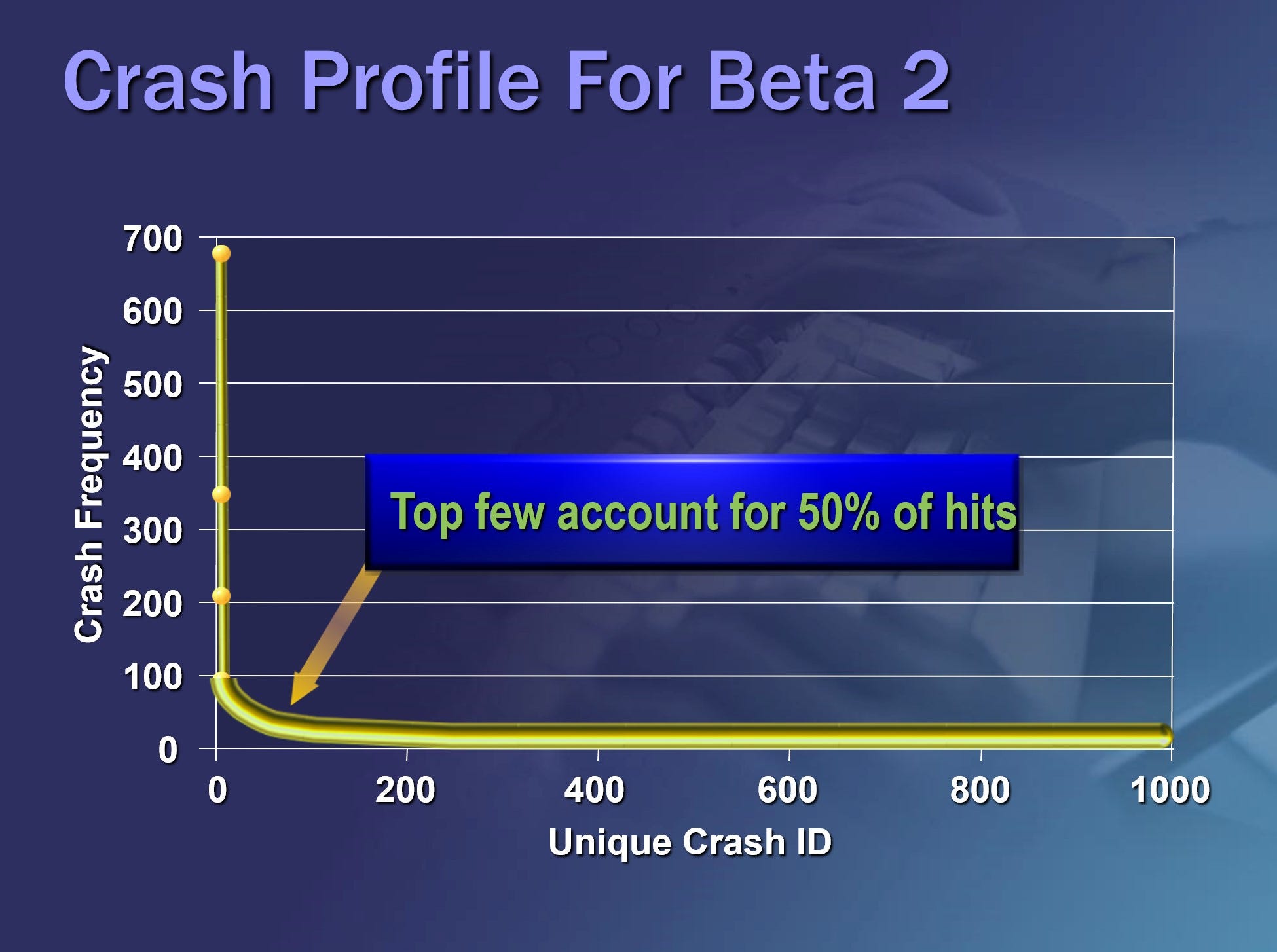
Watson buckets were such that the 20 percent or so of most frequently occurring crashes accounted for more than 80 percent of all experienced crashes. This 80/20 rule is known mathematically as a Pareto distribution, but we lovingly called it the Watson Curve.
Soon in the development of Office10, thousands of CAB files were uploaded. Watson upended our development process. Testers saw crashing bugs in real-world experiences and, as a result, directed testing efforts to features causing the most buckets. Development managers were looking at bugs in the bug database and trying to understand the source. Was the bug found by testing, a person elsewhere, or Watson? Watson streamlined our own bug workflow so that engineers could go straight from the crash to the CAB file details to the debugger in one step. The internal website http://watson became a major part of the engineering process—anyone could visit the site and see the details on a bug (all information was unidentifiable, and the site was secured to members of the development team).
During early beta testing of Office10, Adobe released an update to their popular Acrobat product. In the update they added a toolbar to Office apps to make it easy to create PDF files. Unfortunately, there was a crash in their toolbar for those running the beta of Office10. Fortunately, this crash happened so frequently, and Acrobat was so popular, we immediately saw the Watson bucket and got in touch with Adobe. We knew about the crash because of Watson before Adobe even heard of it. Watson soon expanded so independent software makers could easily see how their software was performing in the real world as well.
Watson continued to evolve after finishing Office10, and somewhat in parallel the Windows team developed a companion service for diagnosing bugs in Windows. These systems were combined in a one-plus-one is greater than two combination to become Windows Error Reporting. The Office team continued to operate the internet service and soon became somewhat of a locus for the product groups running full-scale web services. I found myself signing off on huge purchase orders for servers and storage as we were receiving tens of millions of crashes. All of this starting from KirkG’s idea and a server under his desk.
 Large: Ten Years of Implementation and Experience Kirk Glerum, Kinshuman Kinshumann, Steve Greenberg, Gabriel Aul, Vince Orgovan, Greg Nichols, David Grant, Gretchen Loihle, and Galen Hunt Microsoft Corporation One Microsoft Way Redmond, WA 98052 ABSTRACT Windows Error Reporting (WER) is a distributed system that automates the processing of error reports coming from an installed base of a billion machines. WER has collected billions of error reports in ten years of operation. It collects error data automatically and classifies errors into buckets, which are used to prioritize developer effort and report fixes to users. WER uses a progressive approach to data collection, which minimizes overhead for most reports yet allows developers to collect detailed information when needed. WER takes advantage of its scale to use error statistics as a tool in debugging; this allows developers to isolate bugs that could not be found at smaller scale. WER has been designed for large scale: one pair of database servers can record all the errors that occur on all Windows computers worldwide")
In 2011, the results of this cross-company work received one of the first Engineering Excellence Awards, created by JonDe, to reward significant milestones. Raising the visibility even more, the work received a Chairman’s Innovation and Excellence Award from Bill Gates. Finally, in 2011, the work was published in the Association of Computing Machinery journal Communications of the ACM, as Debugging in the (Very) Large: Ten Years of Implementation and Experience, with nine authors across the company including KirkG as a top author, with OPU program manager Steve Greenberg (SteveGr) and others listed. (EricLev left Microsoft and was by then a successful founder of CellarTacker, an oenology website he started as a hobby.)
People used to ask if clicking on that “Send Error Report” button did any good. It absolutely did.
While having a flight data recorder was helpful to the product team, customers were still losing data when Office crashed. EricLev’s team designed Office10’s Document Recovery, extending PowerPoint’s innovative crash recovery to Word and Excel. When a crash happened Office automatically saved the file to a new location and automatically restarted showing the last version of the original file as well as the file just before crash. This lifesaving feature was dubbed “airbags for Office” by the marketing team when describing it to the press.
The period through building Office10 and the following releases saw an unprecedented pivot to building enterprise class software. While we started selling enterprise software with Office 97, it took time to catch up in the product team. We changed our engineering practices and built out engineering processes that were as mature as anything IBM might have used for mainframes. A decade earlier, if someone suggested we might become more like IBM, I would have been insulted.
The response to Y2K, viruses and malware, crashes, and long-term support were some of our enterprise trials. On the heels of these, Microsoft built out the internet infrastructure to deliver product updates to a billion PCs around the world. This was known as Windows Update. Since that time, everyone has taken the ability to update devices (and machines) for granted, but it was a project years in the making, designed on the heels of scaling to an enterprise company.
Having passed these tests, we had, in the eyes of customers, moved much closer to the coveted trusted enterprise-ready product organization. The industry took note. I could feel the difference with customers and industry analysts and see the difference in how Microsoft was portrayed in trade press when it came to product quality. Expectations rose, but so did our ability to deliver, and to do so proactively. Office markedly improved product quality and we could quantify the improvements with the number of bugs fixed before shipping and with the real-world crashes experienced by customers declining.
Over future releases the role of telemetry would expand dramatically, first to better creating help and how-to content and then to measuring the usage of the product at an extremely granular level (commands, keyboard shortcuts, toolbar buttons, etc.). Watson was even used to further our efforts at securing the PC by tracking crashes that were used as vulnerabilities by bad actors. Through this evolution we maintained a rock-solid privacy approach and by and large the role of this telemetry was accepted. We had gone from essentially guessing about product quality to reacting to being proactive and understanding at a very deep level how our products were used by nearly everyone. While it might sound like hyperbole today, I stand by the language I used on college campuses and this work was a huge step in applied computer science.
We executed well through Office10 M1, M2 approaching the tail of the release. We were a team of 1,500 full-time engineers at that point. Gradually, code stopped changing, and bugs triaged. Execution and precision were at all-time highs. The product was stable. Everyone was using it all the time. This felt great.
I still worried that we could spin out of control—projects at scale do that. Or maybe forces outside the company work to spin us out of control?
On to 062-063. Antitrust: Split Up Microsoft / Managing The Verdict
The Macintosh operating system lagged significantly behind Windows when it came to advances in protecting programs from causing other programs to crash. This had the perverse effect of making Macintosh appear more reliable as they seemed to crash less than Windows. In fact, Macintosh just crashed after doing more damage as programs could step all over each other for quite some time before the system bomb would appear. Windows had early forms of memory protection, the result of which was an errant program would crash sooner before stepping all over another program.
I spent ten years, nearly half my career at Microsoft, on Watson. I loved every minute of it. It is a common observation that working in large corporations is sclerotic, with orgs opposing each other's efforts. Indeed, Mr. Sinofsky has documented some of these at Microsoft. I would like to offer the opposite: Watson touched every part of Microsoft, and in virtually every instance, I had tremendous support and encouragement. From the product teams through upper management, people wanted us to succeed. We collected a staggering amount of data, did our level best to sort, sift, and distribute it, and watched the results with great satisfaction.
This was a superb section. The "Watson for assistance" triggered so many awesome memories for me, around Content Watson and the Chaiman award of 2004 (I think!).